
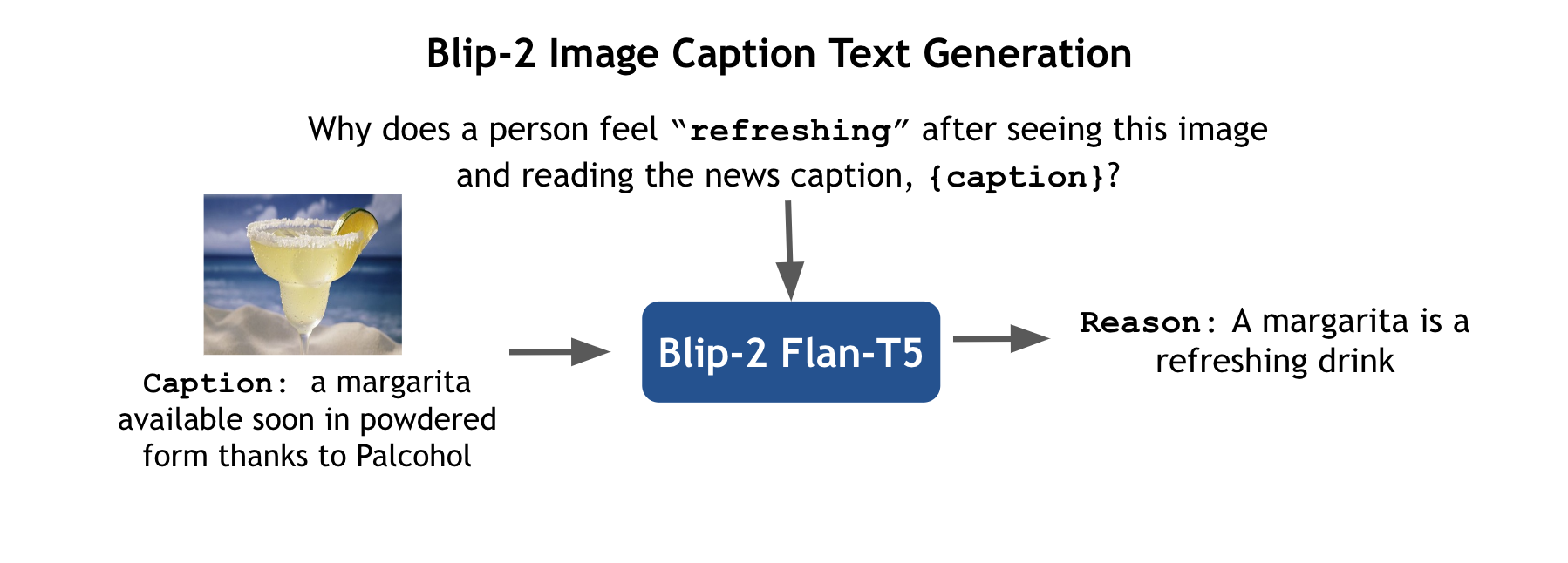
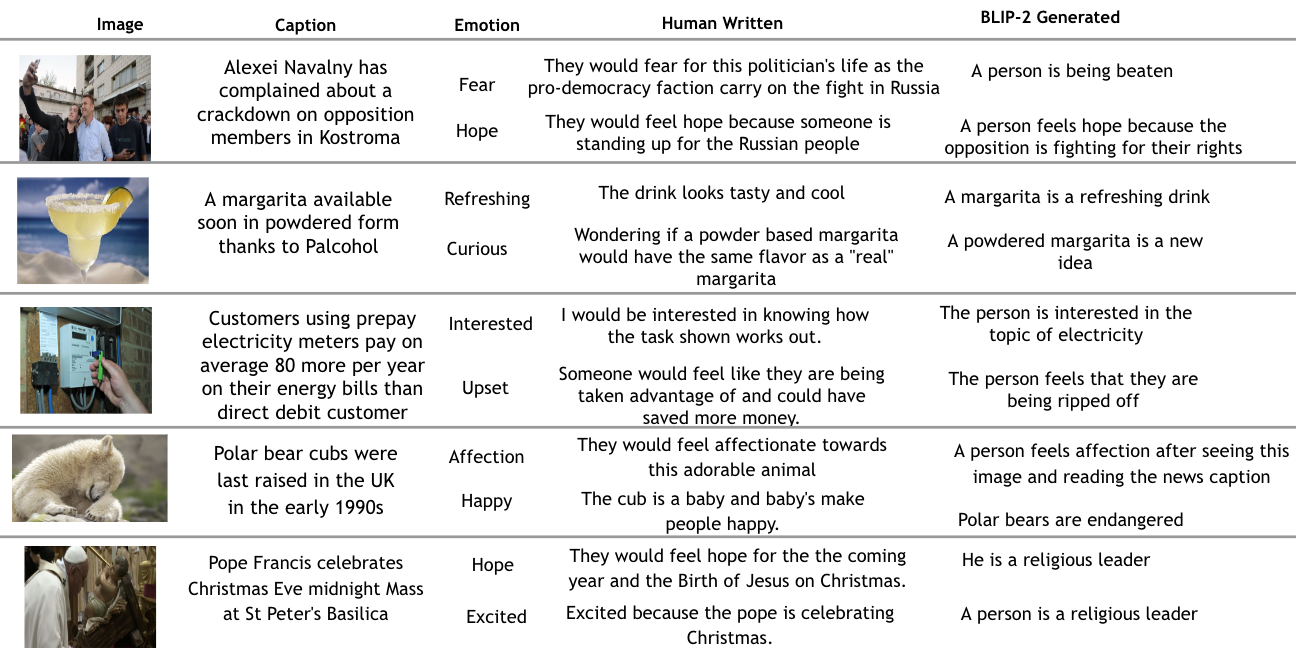
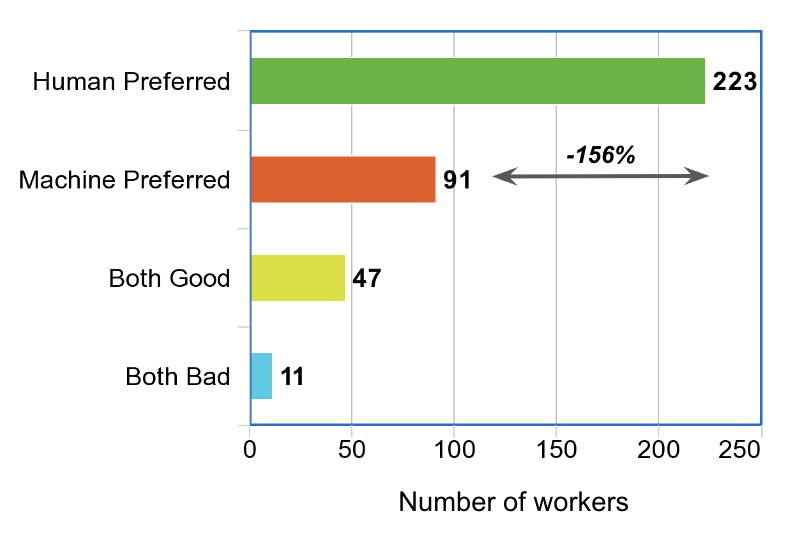

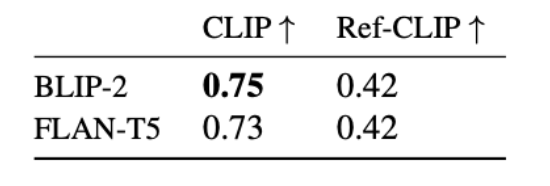
In the future, we look to improve our results by benchmarking more state-of-the-art language and multimodal language models like LLaVA, MiniGPT-4 on our benchmark. Further, we also look to incorporate adaptation methods like in-context learning in multimodal LLMs with example images, captions and explanations.
There's also a lot of similar links that examine empathy and emotions in multimodals.
NICE: Neural Image Commenting with Empathy is a machine learning model designed to generate image captions that exhibit a higher level of emotional understanding and empathy. Unlike conventional image captioning models, NICE aims to provide comments that not only describe the visual content but also consider the emotional context and human-like response. It achieves this by incorporating empathy-aware components into the caption generation process, making it a promising development in improving AI-generated image descriptions.
Can machines learn morality? The Delphi Experiment uses deep neural networks to reason about descriptive ethical judgments, such as determining whether an action is generally good or bad. While Delphi shows promise in its ability to generalize ethical reasoning, it also highlights the need for explicit moral instruction in AI, as it can exhibit biases and imperfections.
ArtEmis: Affective Language for Visual Art is a dataset that comprises 439,000 emotion attributions and explanations for 81,000 artworks from WikiArt. Unlike many existing computer vision datasets, ArtEmis centers on the emotional responses evoked by visual art, with annotators indicating their dominant emotions and providing verbal explanations. This dataset serves as the foundation for training captioning systems that excel in expressing and explaining emotional responses to visual stimuli, often surpassing other datasets in conveying the semantic and abstract content of the artworks.
@misc{deng2023socratis,
title={Socratis: Are large multimodal models emotionally aware?},
author={Katherine Deng and Arijit Ray and Reuben Tan and Saadia Gabriel and Bryan A. Plummer and Kate Saenko},
year={2023},
eprint={2308.16741},
archivePrefix={arXiv},
primaryClass={cs.AI}
}